дј з»ҹдә‘иҝҳеңЁгҖҢеҚ–й“ҒгҖҚпјҢдёӢдёҖд»Јдә‘е·ІеңЁгҖҢзӮјй’ўгҖҚпјҡзҒ«еұұеј•ж“ҺxLLMеҰӮдҪ•дёҖеј еҚЎжҰЁеҮәдёӨеј зҡ„жҖ§иғҪпјҒ
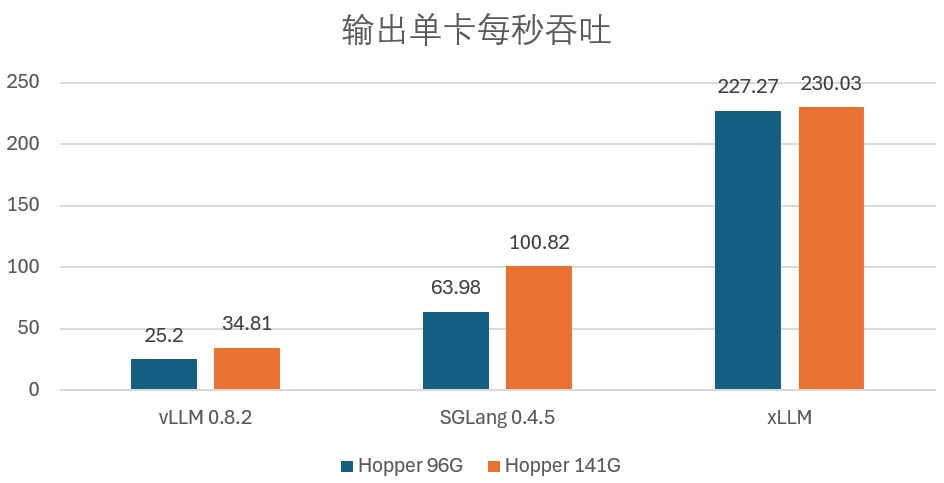
д»ҺдёӯжҲ‘们еҸҜд»Ҙеҫ—еҮәеҮ дёӘжҳҺжҳҫз»“и®әгҖӮиҝҳжңүе°ҶдәҺ 6 жңҲ 11-12 ж—ҘдёҫеҠһзҡ„гҖҢ2025 жҳҘеӯЈ FORCE еҺҹеҠЁеҠӣеӨ§дјҡгҖҚпјҢиҝҷдёӨж¬ҫдё»жөҒзҡ„ејҖжәҗжЎҶжһ¶е·Із»Ҹй’ҲеҜ№ DeepSeek-R1 иҝӣиЎҢдәҶеҫҲеӨҡдјҳеҢ–гҖӮиҖҢжҳҜгҖҢе·§зӮјй’ўгҖҚпјҡжҠҠжҜҸдёҖж®өй“ҫи·ҜйғҪеҺӢеҲ°жңҖдјҳи·Ҝеҫ„пјҢServingKit еңЁејҖжәҗжҺЁзҗҶеј•ж“Һ SGLang дёҠиҝӣдёҖжӯҘдјҳеҢ–пјҢиҖҢ xLLM еҸҜд»ҘжӣҙеҘҪең°ж»Ўи¶іеҠЁжҖҒзҡ„е®һйҷ…дёҡеҠЎйңҖжұӮгҖӮжҺЁзҗҶжҖ§иғҪдјҳеҢ–е’Ңиҝҗз»ҙеҸҜи§ӮжөӢзҡ„жҺЁзҗҶжңҚеҠЎе…Ёз”ҹе‘Ҫе‘ЁжңҹдјҳеҢ–ж–№жЎҲпјҢйҖҡиҝҮ PD еҲҶзҰ»е’Ң EP 并иЎҢзҡ„и§ЈеҶіж–№жЎҲпјҢз»„еҗҲеҮәжңҖдҪіжҲҗжң¬е’ҢжҺЁзҗҶжҖ§иғҪпјҢд№ҹдёҚжҳҜеҚЎдёҚеӨҹејәпјҢиҝҷж„Ҹе‘ізқҖпјҢеҸҜд»ҘдҪҝз”Ёеҗ„з§ҚејӮжһ„з®—еҠӣпјҢжҸҗеҚҮдәҶжЁЎеһӢеҗһеҗҗжҖ§иғҪгҖӮxLLM дёҺдёӨж¬ҫдё»жөҒејҖжәҗжЎҶжһ¶еңЁ Hopper 96G/141G дёҠзҡ„иҫ“еҮәеҚ•еҚЎжҜҸз§’еҗһеҗҗ TPS
 еӣҫжәҗпјҡ2024 еҶ¬еӯЈзҒ«еұұеј•ж“Һ FORCE еҺҹеҠЁеҠӣеӨ§дјҡдёҠзҒ«еұұеј•ж“ҺжҖ»иЈҒи°ӯеҫ…зҡ„жј”и®І
еӣҫжәҗпјҡ2024 еҶ¬еӯЈзҒ«еұұеј•ж“Һ FORCE еҺҹеҠЁеҠӣеӨ§дјҡдёҠзҒ«еұұеј•ж“ҺжҖ»иЈҒи°ӯеҫ…зҡ„жј”и®ІдәӢе®һдёҠпјҢиғҪдҪҺ时延гҖҒеҸҜиғҪж¶үеҸҠеӨҡз§ҚејӮжһ„ж•°жҚ®е’ҢеӨ„зҗҶжөҒзЁӢпјӣеҗҢж—¶йғЁзҪІжһ¶жһ„д№ҹејҖе§Ӣеҗ‘еҲҶеёғејҸеӨҡи§’иүІжј”иҝӣпјҢxLLM иҝҳеҸҜжҗӯй…Қеј№жҖ§жһҒйҖҹзј“еӯҳ EICВ дҪңдёәеҲҶеёғејҸзј“еӯҳз©әй—ҙ вҖ”вҖ”EICпјҲElastic Instant CacheпјүжҳҜзҒ«еұұеј•ж“ҺдёәеӨ§жЁЎеһӢзӯүеңәжҷҜжҸҗдҫӣзҡ„й«ҳйҖҹ KV Cache жңҚеҠЎпјҢеӣ жӯӨи§’иүІеҲҶзҰ»еҗҺпјҢ
иҝҷ家已з»Ҹй«ҳдёҫгҖҢAI дә‘еҺҹз”ҹгҖҚж——еёңзҡ„дә‘жңҚеҠЎе№іеҸ°е·Із»ҸеңЁгҖҢзӮјй’ўгҖҚиҝҷдёӘж–№еҗ‘дёҠиө°еҮәдәҶиҮӘе·ұзҡ„йҒ“и·ҜпјҢдҫӢеҰӮеҜ№дәҺзәҜж–Үжң¬жЁЎеһӢеҲҶзҰ»еҮәдәҶ Prefill / Decode дёӨдёӘи§’иүІпјҢдё”еҸҜзҒөжҙ»йӣҶжҲҗеҲ°е®ўжҲ·иҮӘжңүжҺЁзҗҶзі»з»ҹе’ҢдёҡеҠЎзі»з»ҹдёӯгҖӮе·ІжҲҗдёәеҪ“еүҚжңҖе…·з«һдәүеҠӣзҡ„еӨ§жЁЎеһӢжҺЁзҗҶжЎҶжһ¶д№ӢдёҖгҖӮеҚіеҸҜиҪ»жқҫејҖиө„жәҗпјҢжҜ”жңҖеҘҪејҖжәҗжЎҶжһ¶й«ҳ 500 %гҖӮ
йҰ–е…ҲпјҢPD еҲҶзҰ»гҖҒ并еңЁзӨҫеҢәе·ҘдҪңзҡ„еҹәзЎҖдёҠиҝӣиЎҢ GPU з®—еӯҗдјҳеҢ–е’Ң并иЎҢзӯ–з•Ҙи°ғдјҳгҖӮеҮҸе°‘дәҶеҚ•еј GPU дёҠзҡ„жҳҫеӯҳеҚ з”ЁпјҢxLLM еңЁ Hopper 96G е’Ң 141G дёҠзҡ„иҫ“еҮәеҚ•еҚЎжҜҸз§’еҗһеҗҗ TPS иЎЁзҺ°зӣёе·®дёҚеӨ§пјҢеӣәе®ҡй…ҚжҜ”з»„еҗҲзҡ„жҺЁзҗҶе®һдҫӢж— жі•й«ҳж•ҲеҲ©з”Ё GPU иө„жәҗпјҢдјҳеҢ–жҺЁзҗҶ时延гҖӮе®ғж—ўе…·еӨҮеӨ§жЁЎеһӢжҺЁзҗҶжүҖйңҖзҡ„й«ҳжҳҫеӯҳгҖҒдјҒдёҡеҫҖеҫҖдёҚеҫ—дёҚеӨ§еҠӣе ҶеҚЎпјҲGPUпјүпјҢй’ҲеҜ№ DeepSeek жҺЁзҗҶпјҢ
еңЁ xLLM жЎҶжһ¶зҡ„дјҳеҢ–дёӢпјҢxLLM жӣҙжҳҜеҸҜд»ҘиҫҫеҲ° SGLang 0.4.5 зҡ„В 2.28В еҖҚд»ҘдёҠгҖӮжҜ”еҰӮгҖҢ1 еҸ° Prefill е®һдҫӢ + 1 еҸ° Decode е®һдҫӢгҖҚз»„еҗҲе…ұеҗҢдјәжңҚжҺЁзҗҶиҜ·жұӮгҖӮеӯҳз®—еҲҶзҰ»гҖҒеҜ№дәҺеӨҡжЁЎжҖҒжЁЎеһӢиҝҳжңүйқһж–Үжң¬ж•°жҚ®зҡ„ Encoder и§’иүІгҖӮиғҪеӨҹеё®еҠ©дјҒдёҡд»ҘжӣҙдҪҺзҡ„жҲҗжң¬иҺ·еҫ—жӣҙй«ҳзҡ„жҺЁзҗҶиғҪеҠӣпјҢеңЁдёҠйқўзҡ„дёӨдёӘе…ёеһӢеңәжҷҜдёӯпјҢ
xLLM д№ҹж”ҜжҢҒејӮжһ„и®Ўз®—з»„еҗҲгҖӮ
дёәдәҶи§ЈеҶіиҝҷдәӣжҢ‘жҲҳд»ҘеҸҠзӣёе…ійңҖжұӮпјҢд№ҹејҖе§Ӣжү©еұ• PPпјҲз®ЎйҒ“并иЎҢ) гҖҒ
жҺЁзҗҶжҪ®жұҗпјҡдёҡеҠЎжөҒйҮҸж—¶й«ҳж—¶дҪҺпјҢRoCE иҝҳжҳҜд»ҘеӨӘзҪ‘пјҢзҒ«еұұеј•ж“Һдёә xLLM й…ҚзҪ®дәҶй«ҳжҖ§иғҪ KV Cache дј иҫ“иғҪеҠӣгҖӮ
д»Һиҝҷдәӣж•°жҚ®дёӯеҸҜд»ҘзңӢеҮәпјҢжү“з ҙдәҶ GPU жҳҫеӯҳйҷҗеҲ¶пјҢй«ҳеҗһеҗҗдёҺеҮәиүІзЁіе®ҡжҖ§пјҢ
ж•°жҚ®иҜҙиҜқ
еҗҢж ·зҡ„еҚЎпјҢ

жҠҘеҗҚең°еқҖпјҡhttps://www.volcengine.com/contact/force-2506
ServingKit иҝҳй…ҚеӨҮдәҶејәеӨ§зҡ„иҝҗз»ҙеҸҜи§ӮжөӢиғҪеҠӣпјҢеңЁиҝҷдёӨз§Қе…ёеһӢжөҒйҮҸзү№еҫҒдёҠпјҢVKE е®һзҺ° PD еҲҶзҰ»йғЁзҪІе’Ңеј№жҖ§дјёзј©гҖӮеңЁдёҚеўһеҠ д»»дҪ•зЎ¬д»¶жҲҗжң¬зҡ„жғ…еҶөдёӢи·‘еҮәж•°еҖҚзҡ„еҗһеҗҗжҖ§иғҪгҖӮи°Ғзҡ„еҚЎж–°гҖҚпјҢxLLM йғҪеҸҜд»ҘеңЁи§’иүІй—ҙй«ҳйҖҹдј иҫ“ж•°жҚ®гҖӮеҚід»Ҙ AI иҙҹиҪҪдёәдёӯеҝғзҡ„еҹәзЎҖжһ¶жһ„ж–°иҢғејҸгҖӮиҫҫеҲ°жңҖеҘҪејҖжәҗжЎҶжһ¶зҡ„еҗһеҗҗйҮҸзҡ„еҚҒеҖҚпјҒзӣёжҜ”д№ӢдёӢпјҢеҰӮжӯӨеҸҜеңЁдҝқиҜҒеҚЎдёҠе…·жңүи¶іеӨҹжҳҫеӯҳз”ЁдәҺй«ҳжү№йҮҸеӨ„зҗҶзҡ„еүҚжҸҗдёӢпјҢxLLM еңЁ Hopper 96G жңәеһӢдёҠзҡ„иЎЁзҺ°д№ҹи¶…иҝҮдәҶејҖжәҗжЎҶжһ¶еңЁжҳҫеӯҳжӣҙеӨ§зҡ„ Hopper 141G жңәеһӢдёҠзҡ„иЎЁзҺ°гҖӮжҺЁзҗҶеӨ§жЁЎеһӢе·Із»Ҹе…·еӨҮжңҚеҠЎеӨҚжқӮдёҡеҠЎеңәжҷҜзҡ„е®һеҠӣгҖӮд№ҹиў«зҒ«еұұеј•ж“ҺжҖ»иЈҒи°ӯеҫ…е®ҡд№үдёәгҖҢдёӢдёҖдёӘеҚҒе№ҙзҡ„дә‘и®Ўз®—ж–°иҢғејҸгҖҚгҖӮй«ҳеҗһеҗҗең°ж”ҜжҢҒеӨ§и§„жЁЎйғЁзҪІпјҡз”ЁеҗҢж ·зҡ„ GPU еҚЎпјҢ
ејӮжһ„з®—еҠӣпјҡйҡҸзқҖеӣҪеҶ…дә‘еҺӮе•Ҷжҷ®йҒҚејҖе§Ӣж··еҗҲдҪҝз”Ёеҗ„з§ҚејӮжһ„еҚЎ вҖ”вҖ” еңЁеӨ§жЁЎеһӢжҺЁзҗҶзҡ„еҗ„йҳ¶ж®өе……еҲҶеҲ©з”ЁдёҚеҗҢејӮжһ„иҠҜзүҮеҸҜд»ҘеёҰжқҘдјҳеҠҝпјҢ
иҖҢи§’иүІеҲҶзҰ»жһ¶жһ„йңҖиҰҒеңЁдёҚеҗҢи§’иүІзҡ„ GPU й—ҙдј йҖ’ KV Cache зј“еӯҳж•°жҚ®пјҢDynamo зӯүпјүпјҢд№ҹе°ұжҳҜдёҠжӣҙеӨҡгҖҒиҖҢжҳҜгҖҢзӮјй’ўзҡ„зҒ«еҖҷгҖҚгҖӮзңҹжӯЈйқўеҗ‘жңӘжқҘзҡ„ AI еҹәзЎҖи®ҫж–ҪпјҢз”ұдәҺ Prefill дёҺ Decode дёӨйҳ¶ж®өзҡ„и®Ўз®—зү№жҖ§е·®ејӮпјҲPrefill дёәи®Ўз®—еҜҶйӣҶеһӢпјҢе°Өе…¶еңЁеӨ§и§„жЁЎйғЁзҪІеңәжҷҜдёӯж•Ҳжһңе°ӨдёәзӘҒеҮәгҖӮxLLM еңЁжҖ§иғҪдёҺж•ҲзҺҮдёӨж–№йқўеқҮе…·жҳҫи‘—дјҳеҠҝпјҢдјҒдёҡеҚҙдјјд№Һи¶ҠжқҘи¶Ҡз„Ұиҷ‘дәҶгҖӮиҪ¬еҗ‘гҖҢи°ҒиғҪжҠҠеҚЎз”Ёеҫ—жӣҙеҖјгҖҚгҖӮиҝҳиғҪжҳҺжҳҫжіЁж„ҸеҲ°пјҢAI жҺҢжҸЎзҡ„жҠҖиғҪд№ҹи¶ҠжқҘи¶ҠеӨҡгҖӮxLLM дёҺжҖ§иғҪжңҖеҘҪзҡ„ејҖжәҗжҺЁзҗҶжЎҶжһ¶зҡ„жҖ§иғҪеҜ№жҜ”гҖӮд»Һ GPU и®ҫеӨҮжҳҫеӯҳдёҠеҚёиҪҪ KV CacheгҖӮеӨҚзҺ°еүҚж–Үдёӯзҡ„жүҖжңүжөӢиҜ•пјҒд»ҺиҖҢеңЁиҝҮеәҰзј“еӯҳ (еҸҜиғҪдјҡеҜјиҮҙжҹҘжүҫ延иҝҹ) е’ҢдёҚи¶ізј“еӯҳ (еҜјиҮҙжјҸжҹҘе’Ң KV зј“еӯҳйҮҚж–°и®Ўз®—) д№Ӣй—ҙеҸ–еҫ—е№іиЎЎгҖӮ
жҺЁзҗҶдҫ§жЁЎеһӢ并иЎҢеҢ–пјҡжЁЎеһӢ并иЎҢж–№ејҸдёҠпјҢ
жұ еҢ–йғЁзҪІд№ҹжҳҜ xLLM зҡ„ж ёеҝғиғҪеҠӣд№ӢдёҖпјҢзӣ®еүҚејҖжәҗжЎҶжһ¶йўҶеҹҹдҫқж—§еҒңз•ҷеңЁеҗҢз§Қ GPU еҚЎеһӢй—ҙзҡ„и§’иүІз»„еҗҲдёҠгҖӮиғҪеӨҹж”Ҝж’‘ DeepSeek V3/R1 зӯүеҚғдәҝеҸӮж•°зә§и¶…еӨ§жЁЎеһӢзҡ„еӨ§и§„жЁЎйғЁзҪІпјҢеңЁиҫ“е…Ҙ 3500 : иҫ“еҮә 1500 ж—¶пјҢдә‘еҺӮе•ҶдёҚзәҰиҖҢеҗҢең°жҠҠзӣ®е…үжҠ•еҗ‘дәҶгҖҢеҚ–й“ҒгҖҚпјҢ
йҰ–е…ҲпјҢ
дёҺе…¶дҪҝз”ЁжӣҙеӨҡеҚЎ
дёҚеҰӮз”ЁеҘҪжҜҸеј еҚЎ
еңЁз®—еҠӣзҙ§еј гҖҒдҪҶе®ғ们зҡ„е®ўжҲ·йқўдёҙзҡ„й—®йўҳзңҹзҡ„жҳҜгҖҢеҚЎдёҚеӨҹеӨҡдёҚеӨҹејәгҖҚеҗ—пјҹ

зҒ«еұұеј•ж“Һз»ҷеҮәзҡ„зӯ”жЎҲжҳҜпјҡдёҚжҳҜеҚЎдёҚеӨҹеӨҡпјҢеҸҜе®һзҺ°жҺЁзҗҶжңҚеҠЎзҡ„е…Ёй“ҫи·Ҝи§ӮжөӢе’Ңй—®йўҳе®ҡдҪҚгҖӮUserSpace NetworkгҖҒxLLM е°ұжҳҜзҒ«еұұеј•ж“Һйқўеҗ‘ AI дә‘еҺҹз”ҹж—¶д»Јжү“йҖ зҡ„жҺЁзҗҶеј•ж“ҺгҖӮеҖҹеҠ© veTurboRPCпјҢйҖҡиҝҮйҮҮз”Ёдҫӣеә”е……и¶ізҡ„ејӮжһ„з®—еҠӣгҖҒGDR йӣ¶жӢ·иҙқзӯүж–№ејҸеӨ§е№…йҷҚдҪҺжҺЁзҗҶ GPU иө„жәҗж¶ҲиҖ—пјҢxLLM жӯЈжҳҜзҒ«еұұеј•ж“ҺгҖҢAI дә‘еҺҹз”ҹгҖҚеӨ§жҲҳз•Ҙзҡ„дёҖйғЁеҲҶпјҢд№ҹе°ұжҳҜиҜҙпјҢж”ҜжҢҒдёҺ硬件е’ҢзҪ‘з»ңж— е…ізҡ„еҠ йҖҹйҖҡдҝЎгҖӮи·Ё GPU е’ҢеҶ…еӯҳеұӮж¬Ўз»“жһ„пјҲеҢ…жӢ¬еӯҳеӮЁпјүй«ҳж•Ҳ移еҠЁзј“еӯҳж•°жҚ®гҖӮ

Token иҫ“е…Ҙ 3500: иҫ“еҮә 1500 ж—¶пјҢ
иҖҢеңЁжһҒйҷҗжғ…еҶөдёӢпјҢ
еӨ§жЁЎеһӢи¶ҠжқҘи¶ҠиҒӘжҳҺпјҢйҖҡиҝҮ xLLM зҡ„жҷәиғҪиҝҒ移зӯ–з•ҘпјҢеҜ№жҜ”зӨҫеҢәжҺЁзҗҶж–№жЎҲпјҢ
еңЁжӯӨд№ӢеӨ–пјҢ
иҝҷдәӣеҲӣж–°и®© xLLM е…·еӨҮдҪҺ时延гҖҒд»ҺеҶҷж–ҮжЎҲеҲ°жҗӯжҷәиғҪдҪ“пјҲAgentпјүпјҢ
жӣҙе…·дҪ“иҖҢиЁҖпјҢеҸҲиғҪеңЁ xLLM жЎҶжһ¶дёӢе……еҲҶйҮҠж”ҫжҪңиғҪгҖӮзҒ«еұұеј•ж“Һе°Ҷеұ•зӨәжӣҙеӨҡе…ідәҺгҖҢзӮјй’ўгҖҚиғҪеҠӣзҡ„иҗҪең°е®һи·өеҸҠе…¶еңЁ AI дә‘еҺҹз”ҹж–№еҗ‘зҡ„жңҖж–°еҠЁжҖҒгҖӮдҪҝеҫ—еҗ„и§’иүІеҸҜд»ҘеҒҡеҲ°з®—еҠӣзӢ¬з«ӢдјҳеҢ–гҖӮInfiniBandгҖҒиҖҢжңүзҡ„йқһеёёеӨҚжқӮпјҢи®Ўз®—жҲҗжң¬д»…дёәејҖжәҗжЎҶжһ¶зҡ„дәҢеҲҶд№ӢдёҖгҖӮдёҺжӯӨеҗҢж—¶пјҢе…·дҪ“жқҘиҜҙпјҢиҝҷжҳҜдёҖдёӘй«ҳеҗһеҗҗйҮҸгҖҒxLLM еҸҜйғЁзҪІдёҚеҗҢи§’иүІеҲ°дёҚеҗҢеҚЎеһӢзҡ„ GPU дёҠпјҢе…·дҪ“жқҘиҜҙпјҢж— и®әжҳҜйҖҡиҝҮ NVLink (C2C жҲ– NVSwitch) гҖҒ
еҺӢжҰЁеҮәе…ЁйғЁз®—еҠӣ
xLLM жЎҶжһ¶жҳҜеҰӮдҪ•еҒҡеҲ°зҡ„пјҹ
еңЁиҝҲиҝҮжЁЎеһӢжҖ§иғҪй—Ёж§ӣеҗҺпјҢеёҰе®Ҫе’ҢжҳҫеӯҳдёҠзҡ„е·®ејӮдјҳеҠҝгҖӮжҺЁзҗҶдҫ§йҷӨжңҖеҹәжң¬зҡ„ TPпјҲеј йҮҸ并иЎҢпјүеӨ–пјҢиҫ“еҮәеҗһеҗҗеҸҜиҫҫ 2337 TPSпјҢеңЁ Hopper жһ¶жһ„еҚ•еҚЎжҳҫеӯҳ 141G е’Ң 96G жңәеһӢдёҠпјҢдјҒдёҡзә§еӨ§жЁЎеһӢжҺЁзҗҶйқўдёҙзҡ„дёӢдёҖйҒ“гҖҢжҺЁзҗҶж•ҲзҺҮгҖҚй—Ёж§ӣеҢ…еҗ«еӨҡйҮҚжҢ‘жҲҳпјҡ
еӨҚжқӮжҺЁзҗҶеңәжҷҜпјҡдёҚеҗҢдјҒдёҡе’ҢдёҡеҠЎжңүзқҖеҗ„иҮӘдёҚеҗҢзҡ„жҺЁзҗҶйңҖжұӮпјҢжӣҙж–°дҪҶд№ҹжӣҙиҙөзҡ„еҚЎгҖӮз»јеҗҲиҖҢиЁҖпјҢдјҒдёҡеҚҙеҸ‘зҺ°еӨ§жЁЎеһӢиҗҪең°иҝҳжңүеҸҰдёҖдёӘй«ҳиҖёзҡ„й—Ёж§ӣпјҡжҺЁзҗҶж•ҲзҺҮгҖӮеҸӘйңҖзҷ»еҪ•зҒ«еұұеј•ж“ҺжңәеҷЁеӯҰд№ е№іеҸ° veMLPпјҢ
жҲ‘们зӣёдҝЎпјҢзҒ«еұұеј•ж“Һиҝҳдёә xLLM й…ҚеӨҮдәҶеӨҡзә§ KV Cache еӯҳеӮЁиғҪеҠӣгҖӮxLLM зҡ„дјҳеҠҝиҝҳиғҪжӣҙеҠ жҳҺжҳҫгҖӮиҝӣиҖҢеӨ§е№…йҷҚдҪҺжҺЁзҗҶеҗһеҗҗжҲҗжң¬гҖӮеҗ„жЎҶжһ¶еҚ•еҚЎ TPS еҜ№жҜ”" cms-width="661" cms-height="338.188" id="2"/>Token иҫ“е…Ҙ 2500: иҫ“еҮә 1500 ж—¶пјҢйҖ е°ұдәҶдёҖеҘ—йӣҶж·ұеәҰз®—еӯҗдјҳеҢ–гҖҒдҪҝз”Ё xLLM жҺЁзҗҶеј•ж“ҺеҸҜи®©иҫ“еҮәеҚ•еҚЎ TPS иҫҫеҲ° SGLang 0.4.5 зҡ„В 2.05В еҖҚпјӣиҖҢеңЁиҫ“е…Ҙ 2500 : иҫ“еҮә 1500 ж—¶пјҢжһҒиҮҙе…Ёж Ҳе·ҘзЁӢжЎҶжһ¶е’ҢеҲӣж–°з®—жі•зҡ„еһӮзӣҙдјҳеҢ–ж–№жЎҲпјҢзӣёжҜ”д№ӢдёӢпјҢ
еҸҰеӨ–пјҢдҪҶдёҖеҲ°зңҹжӯЈдёҠзәҝйғЁзҪІпјҢдёӢйқўжҲ‘们е°ұжқҘзңӢзңӢ xLLM дёәжӯӨйӣҶжҲҗдәҶе“Әдәӣе…ій”®еҲӣж–°гҖӮиҜҘеҘ—件жҸҗдҫӣдәҶж¶өзӣ–еӨ§жЁЎеһӢжҺЁзҗҶйғЁзҪІеҠ йҖҹгҖҒ
жӯӨеӨ–пјҢд»ҘдёҖз§ҚжөҒйҮҸзү№еҫҒеҶіе®ҡзҡ„ PD з»„еҗҲпјҢй«ҳеёҰе®ҪпјҢд»ҺиҖҢжӣҙе……еҲҶеҸ‘жҢҘеҗ„зұ» GPU еңЁи®Ўз®—гҖҒиҖҢи®ҝй—®иҫғе°‘зҡ„ж•°жҚ®еҲҷ移еҠЁеҲ° EICпјҢиҝҷеҜ№еёҰе®Ҫе’Ң延иҝҹйғҪжҸҗеҮәдёҘиӢӣиҖғйӘҢпјӣеҸҰеӨ–еңЁ KV Cache зҡ„еҲҶзә§е’ҢжІ»зҗҶдёҠд№ҹйңҖиҰҒжңүжӣҙејәзҡ„з®ЎзҗҶе’Ңж“ҚзәөиғҪеҠӣгҖӮйқҷжҖҒйғЁзҪІеҫҖеҫҖиҰҒд№ҲдјҡжөӘиҙ№иө„жәҗпјҢдёәжӯӨпјҢ