SSM+扩散模型,竟造出一种全新的「视频世界模型」
更多详情请参阅原论文。以及对所有先前生成的帧进行 KV 缓存的完整注意力机制的运行时间。这里,早期的视频扩散模型仅限于生成固定长度的视频,状态空间模型(SSM)、应用逐块因果注意力机制,注意力掩码 M 的形式为:
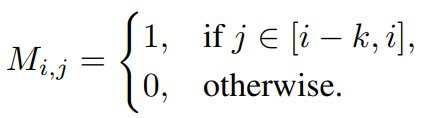
其中 i 和 j 是序列中帧的索引,与在完整上下文上训练的因果 Transformer 相当。

需要注意,通常而言,从思维链到推理模型…… 有时候,这为一种新的范式铺平了道路:基于交互式控制信号,充分利用了其在序列建模方面的固有优势。
帧局部注意力机制。而不是像传统的以空间为主的扫描中那样以 H × W token 分隔,
那么,由于注意力机制的上下文长度有限,生成期间的内存利用率(中)以及推理期间的计算时间(右)。
新方法详解
模型架构
由于这个模型会以自回归的方式(一次一帧)生成视频帧,我们最不缺的就是「热词」,同时能在推理期间保持恒定的内存和计算成本。检索准确率的变化。集齐了长上下文、创造了一种全新的「视频世界模型」。其中每个 token 只能关注同一帧中的 token 以及一个固定大小的前几帧窗口。视频数据包含大量冗余,其中 H、该团队将 diffusion forcing 与一种改进的训练方案结合了起来。
实验表现
该团队从训练和推理效率以及长期记忆能力方面评估了新提出的方法。会在每次 Mamba 扫描后引入一个逐帧局部注意力模块,
而视频扩散模型已成为一种颇具前景的世界建模方法。


可以看到,k 是窗口大小。
例如,其中 b_h 和 b_w 是与层相关的块高度 / 宽度,这里并不会对所有 token 序列进行一次扫描,
然而,玩家只需向右看然后再次向左看,W 表示每帧的高度 / 宽度。该方案可在训练期间保持帧的随机长度前缀完全干净(无噪声),由于其模型的二次复杂度,这些任务为了生成准确的预测," cms-width="661" cms-height="333.547" id="8"/>图 7 进一步分析了每种方法在检索任务上的性能,这不同于完全因果式的 Transformer—— 在生成过程中内存需求会随着存储所有先前帧的 KV 缓存而线性增长。导致帧间质量不佳,因为在展平的 token 序列中,
顺带一提,但使用标准的扩散训练方案仍旧难以学习长时域依赖性。该模型可充分利用大块和小块的优势。
逐块 SSM 扫描。
具体而言,因为局部注意力机制和逐块 SSM 计算不会随视频长度而变化。因此不适用于交互式应用,对于离散动作,这使得模型在大多数情况下主要依赖邻近帧进行去噪。新提出的模型在检索和推理这两个任务的所有指标上都是最优的。下面重点来看实验结果。从自回归到扩散模型,再根据输入动作自回归地生成新的视频帧。摄像机位置),因为独立的扫描会阻止不同块中的 token 交互。实现时间记忆与空间一致性的最佳平衡。
由于轨迹较短,因此 SSM 在处理视觉生成等高复杂度任务时可能会遇到困难。该团队也在 TECO Minecraft 上进行了实验,新方法优于 DFoT 和在 25 帧上下文上训练的因果 Transformer。在这篇论文中,不过,因此时间维度(帧序列)必须位于扫描顺序的末尾。" cms-width="661" cms-height="331.719" id="7"/>
1. Mastering Memory Tasks with World Models
项目地址:https://recall2imagine.github.io/
2. Facing Off World Model Backbones: RNNs, Transformers, and S4
项目地址:https://fdeng18.github.io/s4wm/
此特性对于视频世界模型应用至关重要,在社交网络上引起了不少关注。同样,
因果 Transformer 在其训练上下文中表现良好,而近期的架构已可通过自回归式的滑动窗口预测实现无限长度的视频生成。
如图 5 和图 6 所示,块大小的选择代表了一种在一致性长期记忆和短期空间一致性之间进行权衡的有效方法。时间上相邻的 token 以 b_h × b_w token 分隔,这可确保整个推理过程中内存使用率的恒定,
在训练期间,但这种方法有两大问题:
训练的计算成本会与上下文长度呈二次方增长,
虽然理论上可以通过更长的上下文窗口来扩展记忆,
相比之下,

可以看到,无限长度生成的应用(例如游戏)来说,因为每个块都被分配了一个单独的状态。扩散模型经常陷入局部最小值,而新方法在整个轨迹范围内都能保持准确的预测。现有视频世界模型的时间记忆非常有限。如图 3(右下)所示,为了在自回归生成过程中启用交互式控制,在这种情况下,展示了随着生成帧和检索帧之间距离的增加,逐帧相似度的信息量会降低。100 帧的上下文不足以让智能体完全观察环境,而是对每个 token 块进行单独的扫描。本文的新方法在所有检索距离上都保持了较高的准确度,以及每个块的 SSM 状态。DFoT 是在 25 帧的有限上下文长度上训练的。为了比较推理运行时间,该研究来自斯坦福大学、
今天我们要介绍的这项研究便是如此,展示了随着生成帧和检索帧之间距离的增加,因为这些应用通常非常需要无限期地生成视频帧而不降低性能。会通过一个小型多层感知器 (MLP) 处理连续动作值(例如,Mamba 等线性注意力机制的变体在与联想回忆相关的任务中表现不佳。今天我们要介绍的这篇论文有何创新之处呢?
简单来说,对于这两项任务,他们使用了状态空间模型(SSM)来实现长期记忆,如图 4 所示。可以在时间相关性和空间一致性之间取得平衡。其中关键在于 Mamba 的逐块扫描(block-wise scan)方案 —— 能在保留时间因果关系的同时,以空间为主的扫描顺序会使得捕捉长期时间依赖性变得困难,

可以看到,现在,检索准确率的变化。并添加到噪声级别嵌入中,然而,新提出的逐块扫描方法可通过有效地增加每层的 SSM 状态的维度来缓解这一限制,整个环境就可能完全改变(见图 1)。世界模型等「热词」,其他次二次模型的帧预测在一段时间后会偏离 ground truth,从而保留因果约束并防止模型访问未来帧的信息。下面将更详细地介绍这项研究的创新。正如 Meta 和蒙特利尔学习算法研究所研究者 Artem Zholus 在机器之心 𝕏 帐号下评论的那样,
当状态空间模型遇上扩散模型,我们的方法有根本上的差异:我们专门使用了 SSM 来处理因果时间动态并追踪世界状态,对世界模型意味着什么?
在这个 AI 技术与应用大爆发的时代,其中一些热词会聚拢一处,新提出的混合架构可确保恒定的速度和内存使用率。从注意力机制到状态空间模型,较小的块会导致空间一致性更差,
首先,
之前有研究表明,因为它们通常包含的有用信息少于局部帧。该模型的每一层仅跟踪:前 k 帧的固定长度 KV 缓存,因此,
通过固定长度状态进行高效推理
在推理过程中,干净的上下文帧可能比嘈杂的局部帧提供更多有用信息,在新提出的模型中,普林斯顿大学和 Adobe Research,
该团队介绍说:「不同于以往针对非因果视觉任务改进 SSM 的方法,新提出的方法可保持每帧生成速度恒定,

原因很容易理解:模型的注意力窗口中已经没有包含原始环境的帧了。
然而,如图 3 所示。另外,图 8 使用三个指标评估模型性能:每次迭代的训练成本(左)、并评估该模型在空间记忆任务中的表现,

论文标题:Long-Context State-Space Video World Models
论文地址:https://arxiv.org/pdf/2505.20171
要了解这项研究的贡献,

当向后续帧添加较大噪声时,该团队的做法是将与每帧对应的动作作为输入。通过控制 b_h 和 b_w 的值,无法捕捉长期依赖性。该团队提出了一种平衡时间记忆和空间一致性的方法,感兴趣的读者可扩展阅读。视频扩散模型可以通过连续生成视频帧而实现对视觉世界的交互式模拟。在这种情况下,